
AIエージェントの仕組みを「3つの層」で理解する ― 設計の勘所をわかりやすく解説

相木 悠一
株式会社croppre 代表取締役 / AI推進パートナー
「自分でAIエージェントを作るとき、一番時間をかけているのはコンテキスト層の設計です。AIに渡す情報を整理し直すだけで、回答の精度が別物になる。プロンプト(指示文)を凝るより、渡す情報を整理する方がはるかに効果が大きい。」
この記事のポイント
- 1AIエージェントの仕組みは「プロンプト・コンテキスト・ハーネス」の3つの層で理解できる。 内側から外側へ広がる入れ子構造で、設計すべきことの全体像が見える
- 2各層の設計判断を、ヘルプデスクAIの実例で追体験できる。 「こういう判断が出てくるのか」と知ることが、自社の設計やベンダー評価の土台になる
- 3ノーコードで作るときも、外注で作るときも、見るべきポイントは同じ。 自分で設計するか、提案を評価するかの違いだけ
AIエージェントをノーコードツールで自社で作る。あるいは、外注でオリジナルのものを開発する。― どちらにしても、「仕組み」を知らないまま進めると、想像もしなかったところで躓きます。
SaaS型の既製品を導入するだけなら、仕組みを知らなくても使えます。しかし「作る」となると話が別です。ノーコードツールでも設計判断は必要ですし、外注でもベンダーの提案の良し悪しを見抜く目がなければ、「よくわからないまま契約して、使いづらくて現場に浸透しなかった」という結果になりかねません。
この記事では、AIエージェントの仕組みを「3つの層」というフレームワークで整理します。そして各層の解説で、私が実際にクライアント企業でヘルプデスクAIを構築したときの設計判断を具体例として当てはめていきます。
抽象的な仕組み解説でもなく、特定業務の話でもなく、「構造 × 具体例」のセットで設計の勘所を掴んでもらう。 それがこの記事の目的です。
「AIが賢い」だけでは、業務を任せられない
AIモデルはどんどん賢くなっています。ChatGPTに質問すれば、たいていのことは教えてくれる。調べものや文章の下書きなど、チャットで聞くだけでも十分助かる場面はたくさんあります。
ただ、「AIエージェントに業務をやってもらう」となると、話が変わります。
たとえば、ChatGPTに「来月の発注書を作って」と頼んでみたとします。それなりの文章は出てくるかもしれない。しかし、自社の取引先マスタを参照して正しい品番を使っているか? 発注量は在庫データに基づいているか? 承認フローに沿って上長に回しているか? ― どれも「NO」です。
「考える」ことはできても、「調べる」「動く」「覚えている」ことはできない。 チャットで聞くぶんには賢いAIも、業務を任せようとした途端に「仕事場」が必要になります。
優秀な新入社員を採用しても、社内ルールを教えず、システムへのアクセス権を渡さず、過去の経緯も共有しなければ、まともに仕事ができないのと同じです。
業界では、この「AIモデルの周りに作り込む仕組み」のことを「ハーネス」と呼んでいます。つまり、
AIエージェント = モデル(考える力)+ ハーネス(仕事場)
ノーコードツールで作るときも、外注するときも、このハーネスをどう設計するかが成否を分けます。 モデルの選択は全体の一部にすぎません。
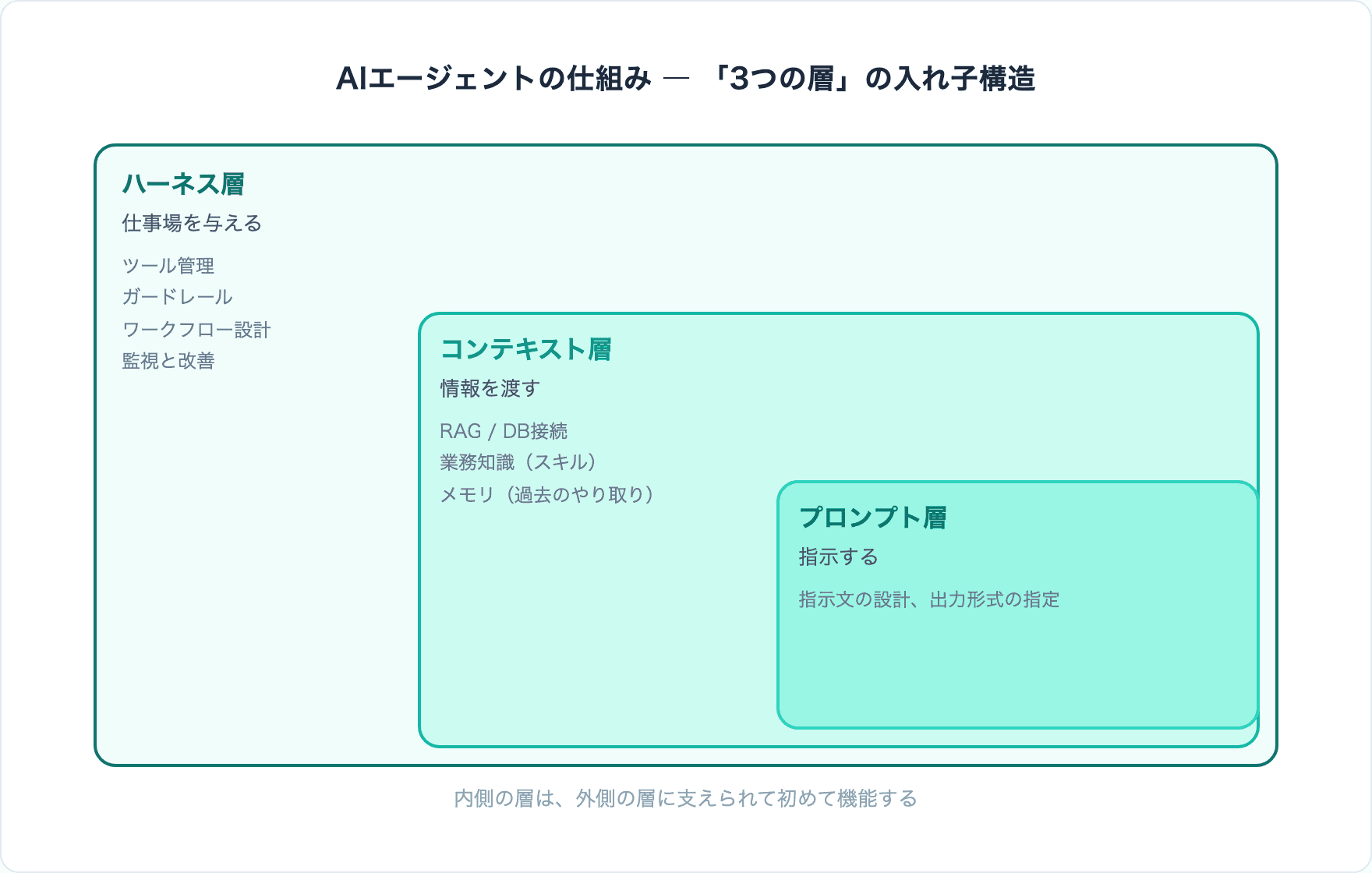
3つの層 ― プロンプト・コンテキスト・ハーネスの入れ子構造
ハーネスの中身を理解するために、AIエージェントの仕組みを「3つの層」で整理します。内側から外側へ広がる入れ子構造です。

| 層 | 一言で | やっていること |
|---|---|---|
| プロンプト(一番内側) | 「指示する」 | AIへの指示の書き方と、出力の形式を決める |
| コンテキスト(中間層) | 「情報を渡す」 | AIに必要な情報を、必要なタイミングで届ける |
| ハーネス(一番外側) | 「仕事場を与える」 | AIが使える道具、やっていい範囲、監視の仕組みを整える |
重要なのは、内側だけでは業務を任せづらいということです。プロンプト(指示)をどれだけ工夫しても、必要な情報が渡されていなければ正確な回答はできない。情報を渡しても、道具や権限がなければ業務を実行できない。内側の層は、外側の層に支えられて初めて機能します。
ここから各層を、ヘルプデスクAIの設計で直面した判断を当てはめながら見ていきます。
プロンプト層 ― AIに「指示する」
プロンプト層は、AIモデルへの指示の書き方と出力の形式を設計するパートです。
「ChatGPTへの質問の仕方を工夫する」― いわゆるプロンプトエンジニアリング。多くの方がイメージする「AI活用」は、実はこの一番内側の層の話です。
プロンプトの工夫だけでも回答の質は変わります。しかし、業務用のAIエージェントにおいては、プロンプトの影響度は全体の一部にすぎません。 その外側の層(情報と仕事場)がどれだけ整っているかが、実際の品質を大きく左右します。
ヘルプデスクAIの場合
ヘルプデスクAIのプロンプト設計では、「丁寧語で回答してください」のような基本的な指示はもちろん入れますが、業務を任せるとなるとそれだけでは足りません。「回答の根拠となる文書名を必ず明示すること」「規定に記載がない質問には『規定に記載がないため、担当部署に確認します』と回答すること」「推測で回答しないこと」― こうした業務上のルールをプロンプトに織り込む必要があります。
ただ、これだけ工夫しても、参照すべき文書が渡されていなければ正確な回答はできません。プロンプト層の限界は、次のコンテキスト層が補います。
作るとき・選ぶときのポイント
ノーコードで作る場合: プロンプトは最初に手をつける箇所ですが、「ChatGPTに質問するように書けばいい」わけではありません。業務ルール(回答できないときの振る舞い、根拠の明示ルール等)をプロンプトに織り込む設計が必要です。
外注で作る場合: プロンプト設計は多くのベンダーが対応できます。差がつくのはむしろ次のコンテキスト層以降です。ただし、「どんな業務ルールをプロンプトに入れるか」は社内の業務知識がないと設計できないため、ベンダー任せにせず自社で要件を出す必要があります。
コンテキスト層 ― AIに「情報を渡す」
コンテキスト層は、AIモデルに「何を知らせた状態で考えさせるか」を設計するパートです。
AIモデルは人間のように「記憶」を持っているわけではありません。毎回、その場で渡された情報だけをもとに考えます。つまり、「何を伝えられたか」がAIの回答の質を決めます。
業界ではこれをコンテキストエンジニアリングと呼んでいます。「どう指示するか」の工夫がプロンプトエンジニアリングなら、コンテキストエンジニアリングは「何を知らせるか」を設計する技術です。
ポイントはシンプルです。「全部渡せばいい」わけではない。 渡す情報が多すぎると、AIは重要な情報を見落とします。100ページの資料を丸ごと渡されるより、要点を3ページにまとめてもらった方が正確に判断できるのは、人間もAIも同じです。
必要な情報を、必要なタイミングで、適切な量だけ渡す ― これがコンテキスト層の設計の勘所です。
ヘルプデスクAIの場合 ― 回答の「よりどころ」は1つではない
実際にヘルプデスクAIを設計したとき、回答のよりどころが質問カテゴリによって全く違うことに気づきました。
| 質問カテゴリ | 回答のよりどころ | なぜそうするか |
|---|---|---|
| 就業規則の問い合わせ(「育休は何日取れますか」) | 社内ドキュメントに厳密に準拠(RAG) | 条文通りに答えなければ大問題。AIの知識で補ってほしくない |
| システムトラブル対応(「VPNが繋がらない」) | AIモデルの知識で補填してよい | 社内ドキュメントに書いてなくても、一般的な対処法を教えてくれた方が助かる |
| ツールの仕様変更(「Teamsの新機能の使い方」) | Web検索で最新情報を取得 | 社内ドキュメントにもAIの学習データにもない最新情報が必要 |
重要なのは、この3つが同じヘルプデスクAIの中で混在するということです。質問のカテゴリによって、回答のよりどころを切り替える設計が必要になります。
「社内データをAIに読み込ませます」の一言で済む話ではないのです。
もう1つの落とし穴 ― 前提情報
システム部のヘルプデスクの場合、社内で使っているツールの一覧、バージョン、設定情報をAIにあらかじめ教えておく必要もあります。「VPNは何を使っていますか」「メールはGmailですかOutlookですか」― こうした前提情報がないと、的外れな回答を連発します。
意外かもしれませんが、「何を知らせるか」の設計が、AIモデルの賢さ以上に回答品質を左右します。
作るとき・選ぶときのポイント
ノーコードで作る場合: 「社内データを読み込ませる」だけで終わらせないこと。質問カテゴリによって回答のよりどころを切り替える設計が必要です。上のヘルプデスクAIの例のように、「どのデータを、どの質問に、どうやって渡すか」を整理するだけで回答品質が大きく変わります。
外注で作る場合: ベンダーの提案で「RAGを導入します」「社内データをAIに接続します」とだけ書いてあったら、もう一歩踏み込んでください。「質問のカテゴリによって参照するデータソースは変わりますか?」「最新情報の取得はどう設計しますか?」と確認することで、提案の解像度が見えます。こうした確認の観点は、AIコンサル・AI導入支援会社の選び方でも詳しく整理しています。
ハーネス層 ― AIに「仕事場を与える」
ハーネス層は、AIエージェントの仕事場全体を整えるパートです。内側の2つの層(プロンプトとコンテキスト)を包み込み、AIが安全に、正確に、想定通りに動くための環境を提供します。AIエージェントの信頼性を決める最大の要因です。
ハーネス層がやっていることを、大きく分けると以下の通りです。
1. ツール管理(道具を渡す)
AIモデルに「メールを送って」と言われたら、本当にメールを送る仕組みが必要です。データベースの検索、ファイルの作成、外部システムへのデータ送信 ― こうした「外の世界とやり取りする」部分を管理します。
ここで重要なのが最小権限の原則。AIエージェントには「必要最低限の権限だけ」を渡す。人間の新入社員にも、入社初日から全システムの管理者権限を渡したりはしないはずです。
ツールは多ければいいわけでもありません。Vercel(ウェブ開発企業)は、AIエージェントに渡すツールを80%削減したところ、成功率が向上しました。ツールが多すぎるとAIは「どれを使うか」で迷い、間違った選択をしやすくなります。制約は味方です。
2. ガードレール(やっていい範囲を決める)
AIは間違えます。これは前提です。大事なのは「間違えたときにどうするか」の設計です。
3. ワークフロー設計(段取りを組む)
複雑な業務を「まずAを調べて、次にBを判断して、結果に応じてCかDに進む」と段階的に分解して実行する仕組みです。
4. 監視と改善(育てる仕組み)
AIエージェントが本番で動き始めた後も、出力の品質を監視し、問題があれば改善する。「作って終わり」ではなく「育てていく」ための仕組みです。
ヘルプデスクAIの場合
実際にヘルプデスクAIを設計したとき、このハーネス層でも多くの設計判断に直面しました。具体的に見ていきます。
間違えたときの対処 ― 1つの方法では足りない
AIの「間違い」は、領域によってリスクがまるで違います。就業規則で「育休は取れません」と間違えたら社員の人生に関わる大問題。一方、「VPNの接続手順」で1ステップ抜けていても、やり直すだけの話です。
だから「AIの回答精度は95%です」と言われても判断できません。残りの5%がどこで起こるかが重要なんです。
実際の設計では、以下のような対処法を検討し、カテゴリごとにどれを使うか選んでいきました。
| 対処法 | 内容 | 例 |
|---|---|---|
| 参照リンクの提示 | AIの回答に根拠となるドキュメントへのリンクをつけ、正確な内容は原本で確認できるようにする | 就業規則の回答に、該当する規定のリンクを添える |
| 人間確認フロー | AIが草案を作り、人間が確認してから送信する | 間違いのリスクが高い領域に適用 |
| 二重チェック | AIの回答を別のAIプロセスが検証する | 参照元文書との整合性を自動チェック |
| 事後レビュー | 日次でAIの対応内容を振り返り、危ないものを洗い出す | リアルタイム確認が不要な領域 |
| 事前テスト | AIで大量の質問を生成し、回答の弱い領域を事前に把握する | リリース前にどの領域が弱いか特定して対策 |
すべてを最初から実装する必要はありません。私たちのケースでも、まず事前テストでどの領域が弱いかを把握し、リスクの高い領域から順に対処法を入れていく、という段階的なアプローチを取っています。どの対処法をどのカテゴリに使うか、濃淡をつけて設計するのが、ハーネス層の腕の見せ所です。
答えられなかったとき ― 「わかりません」で終わらせない
どんなに設計を頑張っても、AIが答えられない質問は出てきます。ここで「回答できません」と返して終わるAIは、すぐに使われなくなります。
実際には、こう設計しました。
- AIが回答できないと判断 → 担当部署に通知が飛ぶ
- 担当者が対応 → 質問者と直接やり取りして解決
- その解決内容が自動でナレッジに還流される
「答えられなかった質問」が自動的にAIの学習素材に変わる仕組みです。使うほど答えられる範囲が広がっていく。 このサイクルがないと「最初は便利だったけど、だんだん物足りなくなってきた」という声に繋がります。
ナレッジの更新 ― 「作って終わり」が一番危ない
ナレッジの追加は誰でもイメージできます。難しいのは、既存のナレッジが古くなったときのメンテナンスです。就業規則が改定されたのに旧版が残っていれば、新旧混在した回答を返す事故が起きる。ツール側のアップデートで対処法が変わったのに、古いナレッジがそのままだと的外れな回答を返し続ける。古い情報を確実に検知・更新できる仕組みまで設計しておかないと、長期運用で信頼性が落ちていきます。
作るとき・選ぶときのポイント
ノーコードで作る場合: ノーコードツールは「簡単に作れる」ことが売りですが、ハーネス層の設計は省略できません。どこまで作り込むかは業務やリスクの性質によりますが、たとえば以下のような観点は検討する価値があります。
- 間違えたときの対処(どのカテゴリはAI単独でOK、どのカテゴリは人間確認が必要か)
- 答えられなかったときの導線(誰にエスカレーションするか)
- ナレッジの更新フロー(誰が、いつ、どう更新するか)
外注で作る場合: ベンダーの提案で「AIの精度は高いので大丈夫です」「最新モデルを使っています」と書いてあったら、もう一歩踏み込んで確認してみてください。
| 確認すべき観点 | 具体的な質問例 | 良い回答の目安 |
|---|---|---|
| 間違いへの対処 | 「AIが間違えたとき、どう検知して、どう修正する設計ですか? カテゴリごとに濃淡はありますか?」 | カテゴリ別にリスクの濃淡を分けた設計が出てくる |
| エスカレーション | 「AIが答えられなかった場合の導線はどうなっていますか? そこからの学習の仕組みはありますか?」 | 「わかりません」で終わらず、人間への引き継ぎとナレッジ還流まで設計されている |
| ナレッジ更新 | 「情報の更新・削除フローは設計されていますか? 最初のデータ投入だけで終わりではないですか?」 | 運用フェーズのメンテナンス体制まで提案に含まれている |
| 権限の範囲 | 「AIがアクセスできるシステムと、できないシステムの線引きはどうなっていますか?」 | 最小権限の原則に基づき、明確な線引きが設計されている |
ここが具体的に設計されているかどうかが、提案の質を分けるポイントです。 「良い回答の目安」と見比べて、具体性があるかどうかを確認してください。複数ベンダーの提案をこの観点で並べてみると、差が一目でわかります。
 相木
相木
自分がベンダーに発注する側だったら、提案書の「できること一覧」だけでなく「エラーが起きたときの設計」も確認します。できることは書きやすいけれど、失敗したときの設計はちゃんと考えていないと書けない。ここが考えられているかが、ベンダーの技術力の目安になります。
「どこまでAIに任せるか」の線引き
3つの層を理解すると、次の疑問が出てきます。「では、具体的にどこまでAIに任せて、どこから人間が見るべきなのか?」
AIエージェントの導入で最もリスクが高いのは、技術的な失敗ではなく、任せる範囲の設計ミスです。
業務を「判断ポイント」で分解する
どの業務にも、人間が判断を下すポイントがあります。まず業務を分解して、判断ポイントを可視化する。その上で「この判断はAIに任せていいか」「ここは人間が見るべきか」を1つずつ決めていく。
ヘルプデスクAIの場合
| ステップ | 判断ポイント | 任せ方 |
|---|---|---|
| 問い合わせ内容の分類 | どのカテゴリに振り分けるか | AIに任せてよい(間違えてもリスク小) |
| 過去の類似質問の検索 | どの回答が参考になるか | AIに任せてよい(回答候補の提示まで) |
| 回答の作成 | 回答内容が正確か | カテゴリによって変える:システムトラブル→AI単独OK、就業規則→AI草案+人間確認 |
| エスカレーション判断 | 担当部署に振るべきか | AIが判断。ただし「自信がない」場合は自動で人間に回す |
| 個人情報を含む対応 | 情報の取り扱い | 人間が対応(AIには個人情報へのアクセスを与えない) |
同じ業務の中でも「AI単独」「AIが下書き+人間確認」「人間が対応」のグラデーションがあります。
段階的に任せる範囲を広げる
業界では、この段階的なアプローチを「段階的自律性」と呼んでいます。
| 段階 | 意味 | 例 |
|---|---|---|
| 「毎回確認」型(Human in the Loop) | AIの出力を毎回確認してから実行 | AIが作った回答を、担当者が確認してから送信 |
| 「見守り」型(Human on the Loop) | AIは自律的に動くが、人間が監視して異常時に介入 | AIが自動回答するが、リスクの高いカテゴリだけ承認フローに回す |
| 完全自律 | 人間の関与なしにAIが完結 | 一定条件下の定型質問は、確認なしにAIが回答 |
どの段階から始めるかは、リスクと精度のバランスで決まります。
リスクが小さくて精度がそこそこ出る業務なら、最初から完全自律で回して様子を見るのもありです。実は開発の観点でも、自動で回答・実行する方が承認フローを組むより工数が少なく済むので、リスクが小さいものから自動化して始めるのは合理的な選択です。
一方、リスクが中程度以上の業務は「毎回確認」型から始めて、実績データが積み上がったら徐々に「見守り」型に移行するなど、業務ごとに段階を使い分けるのがポイントです。
こういう判断が、全部ある
ここまでで、1つのヘルプデスクAIを作るだけでこれだけの設計判断があることが伝わったと思います。
- プロンプト層: 業務ルールをどう指示に織り込むか
- コンテキスト層: どのカテゴリの質問に、どの情報源を使うか。前提情報をどう渡すか
- ハーネス層: 間違えたときどうするか。答えられなかったとき人間にどう繋ぐか。ナレッジをどう育てるか
- 線引き: どこまでAIに任せ、どこから人間が見るか
今回はヘルプデスクAIを例に話しましたが、対象業務が変われば、さまざまな判断ポイントが出てきます。営業支援AIなら顧客情報の取り扱い、カスタマーサポートAIなら対外的な回答の品質管理、経理AIなら法令遵守のチェック。
具体的な答えは業務によって変わります。しかし「3つの層」のどこを設計すべきかという問いの構造は同じです。 この構造を知っていることが、AIエージェントの設計や選定のヒントになれば嬉しいです。
結論 ― 「賢いAI」ではなく「設計の質」にお金を払う
AIエージェントの価値は、AIモデルが賢いことではありません。3つの層にわたる設計判断の積み重ねにあります。
AIの性能はOpenAIやAnthropicの手柄です。ベンダーの本当の実力 ― そしてノーコードで自分たちで作るときの成否 ― は、そのモデルの周りにどれだけ丁寧な仕組みを作れるかにあります。
この記事の観点を持った上で、次のステップに進むなら:
- 内製するか外注するかの判断 → AI内製化か外注か
- パートナーの選び方と評価基準 → AIコンサル・AI導入支援会社の選び方
- 小さく始めるための戦略 → AI戦略の作り方
なお、組織が大きいほど「どの部署から始めるか」「推進体制をどう作るか」の判断も加わります。技術的な設計だけでなく、組織を巻き込む段取りも含めて検討したい場合は、AI戦略の作り方が参考になります。
「何を見ればいいか」がわかった。次は「どう判断するか」「どう選ぶか」です。
AIエージェントの仕組みについてよく聞かれること
ここまで読んでいただいた中で、「うちの場合はどうだろう」と感じているポイントがあるかもしれません。よく聞かれる疑問について、もう少し踏み込んでお話しします。
Q1. この記事の内容は、ヘルプデスクAI以外にも当てはまるのか?
当てはまります。ヘルプデスクAIは具体例として使いましたが、「3つの層」の構造はどんなAIエージェントにも共通です。営業支援AI、社内文書検索AI、カスタマーサポートAI ― 具体的な設計判断は業務によって変わりますが、「プロンプト層・コンテキスト層・ハーネス層のそれぞれで何を設計すべきか」という問いの枠組みは同じです。
Q2. SaaS型のAIエージェント製品を導入する場合は、この記事は不要か?
SaaS型であれば、設計の多くはサービス提供側が担っているため、ここまでの知識がなくても使い始められます。ただし、「このSaaSがうちの業務に合っているか」を判断するときには、3つの層の観点が使えます。「コンテキスト層で自社データをどう扱えるか」「ハーネス層でエラー時の挙動はどうなっているか」を確認するだけでも、選定の精度が上がります。
Q3. 自社にAIの技術者がいなくても、ノーコードで作れるのか?
作れます。ノーコードツールを使えば、プログラミングなしでAIエージェントの「形」は作れます。小規模で試すぶんには、技術者がいなくても十分に始められます。ただし、扱うデータが増える、止まらない安定性が求められる、複数のシステムをまたぐ複雑な仕組みにする ― こうなってくると、設計の重要度が一気に上がります。ノーコードツールが「組み立て」を簡単にしてくれても、「何をどう組み立てるか」の設計は人間の仕事です。「何に答えるAIなのか」「間違えたときどうするか」「ナレッジをどう更新するか」「データが増えたときに検索精度をどう保つか」。こうした判断を経験なしに全部正しくやるのは、正直しんどい。小さく始めて学びながら広げるか、設計部分だけ専門家の力を借りるのが現実的です。
Q4. ベンダーの提案を受けるとき、最低限確認すべきことは?
3つの層それぞれについて1つずつ、合計3つ確認してください。コンテキスト層:「どのデータを、どのタイミングでAIに渡す設計ですか?」 ハーネス層:「AIが間違えたときの検知・対処の仕組みはどうなっていますか?」 線引き:「最初から全自動ですか、段階的に自律範囲を広げる設計ですか?」 この3問で、提案の質がかなり見えます。
Q5. 「コンテキストエンジニアリング」と「プロンプトエンジニアリング」は何が違うのか?
本記事の「3つの層」でいうと、プロンプト層とコンテキスト層の違いがそのまま答えです。プロンプトエンジニアリングは「AIへの指示文をどう書くか」の工夫(一番内側の層)。コンテキストエンジニアリングは「AIに何を知らせた状態で考えさせるか」の設計全体(中間の層)。業務用のAIエージェントでは、後者の方がはるかに影響が大きい。
Q6. 小さく始めるなら、まず何からやるのがいいのか?
対象業務を1つに絞り、その中でも1つのカテゴリだけから始めること。ヘルプデスクの例で言えば、「就業規則」「システムトラブル」「経費精算」のうち1つだけ。全部を一度にやろうとすると、この記事で書いたすべての設計判断が一気に押し寄せます。1つで成功体験を作ってから横展開する方が、結果的に速い。詳しくはAI戦略の作り方で整理しています。
ここまでお読みいただき、ありがとうございました。AIエージェントの仕組みは「3つの層」で整理すると見通しがよくなります。ノーコードで自分で作るにしても、ベンダーに任せるにしても、「何を見ればいいか」がわかっていれば判断が変わります。この記事が、その一歩のきっかけになれば嬉しいです。
この記事を書いた人

相木 悠一
株式会社croppre 代表取締役 / AI推進パートナー
2017年、京都大学在学中にアフリカで創業。4年間、小売業界向けの業務システム開発に従事。
2021年に帰国後、AI開発に軸足を移し、自社業務にAIエージェントを導入して同業比5倍の生産性を実現。その過程で顧客企業から「AI推進の相談役をやってほしい」と声がかかり、中堅企業のAI推進チームの一員として戦略策定からエージェント開発まで伴走する現在のスタイルに至る。
AIグランプリ2025春 イノベイティア賞受賞


自分でAIエージェントを作るとき、一番時間をかけているのはこのコンテキスト層の設計です。AIに渡す情報を整理し直すだけで、回答の精度が別物になる。プロンプト(指示文)を凝るより、渡す情報を整理する方がはるかに効果が大きい。